Reports of Your Death Are Greatly Exaggerated
No, Microsoft did not reveal the 40 jobs “most at risk of being lost to AI”. Everybody take a deep breath.
It’s the 14th very real and human LinkedIn post you’ve scrolled past today:
“The sky is falling! Honestly though? It’s not just falling – it’s plummeting to Earth!”
The post, of course, is hoping to “inform” you about the new1 report from Microsoft detailing the 40 jobs that are “most at risk” of being replaced by AI, and the 40 jobs that are evidently unshackled from the onward march of technology. Article after article has come out with eye-catching titles:
Top 5 Most and Least AI-Safe Jobs
Microsoft says these 7 jobs are going to replaced, and here’s how they know
Pack Up Your Desk, Kevin. Yes You. We’ve Hired Grok’s Girlfriend To Do Advertising.
You’re not being “replaced by AI”
While yes, it’s tragic what happened to Kevin, everyone else is really losing their collective mind over something that the researchers at Microsoft aren’t saying, or even implying.2 In fact, they explicitly warn that this is not the takeaway multiple times.
On the second page of the report, they write, in response to the prevailing public discourse around AI automation vs. task augmentation:
“The implication is that augmentation will raise wages and automation will lower wages or lead to job loss. However, this question often conflates the capability of a new technology with the downstream business choices made as a result of that technology… Our data is only about AI usage and we have no data on the downstream impacts of that usage…”
And again on page 19:
“It is tempting to conclude that occupations that have high overlap with activities AI performs will be automated and thus experience job or wage loss, and that occupations with activities AI assists with will be augmented and raise wages. This would be a mistake, as our data do not include the downstream business impacts of new technology, which are very hard to predict and often counterintuitive.”
The authors offer up the example of ATMs, which were feared to eradicate bank teller as a profession but instead had the opposite effect, increasing the number of teller jobs. The prevailing idea among those writing about this paper is that “applicability” somehow means “interchangeability”, when in fact the authors of this paper seem to be nearly begging people to separate the idea of augmentation from automation, and mention several times that impact scope is consistently lower for AI actions than user assistance.3
AI Applicability Score Components
I am not affiliated with these authors/this paper in any way, and I’m certainly not a reviewer on the paper. I’m simply tossing out my thoughts here, so let’s get into the general concepts used in this report, painting with the extremely broad brush that is my surface level understanding after reading the paper.
In most literature involving labor analytics, occupations are broken down into increasingly broader functions. Any given occupation has multiple tasks that they must do in their day-to-day work. These tasks, as they are defined by O*NET, are ultra-specific and are really only done by those with the associated occupation. Tasks can be generalized into “detailed work activities” (or DWAs) that are then further generalized into “intermediate work activities” (IWAs) before finally being generalized into the broadest category, the most general of them all, “generalized work activities” (GWAs).4
The example given in the paper5 is an economist, and I’m relaying their example table here:
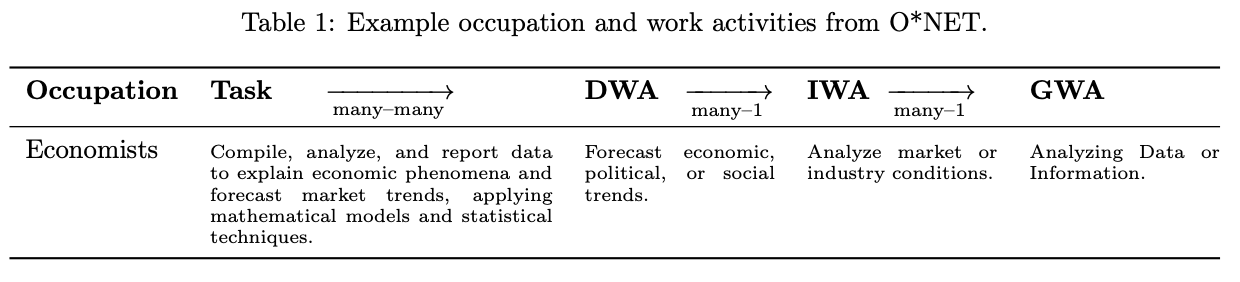
What this paper is essentially doing is extracting these IWAs from a sample of user conversations with Copilot, separating the user goal from the action the AI took, and looking at three things:
Coverage
Coverage is attempting to measure the frequency users are getting assistance for certain IWAs and the frequency of the action being done by AI. It appears that an IWA is considered “covered” in this paper if it shows up in a couple hundred conversations of their 200k conversation sample. These are then weighted by the relevance of that IWA to an occupation.
Let’s say writing this blog post is an occupation. It involves three IWAs: reading the paper (30%), writing snarky things (50%), and procrastinating (20%). A sufficient number of conversations were classified as the AI reading a paper, so that is considered a “covered” IWA. Same goes for writing snark. But luckily, I’m much better at procrastinating than AI is, and AI didn’t procrastinate frequently enough for that IWA to be considered covered. The coverage percentage for the occupation of writing this blog post is then 80%.
Completion
I’ve got some issues with the approach here, but again, I’m not a reviewer and I don’t have a PhD so take what I say with a grain of salt.
Completion is a measure of how successfully the AI completed the work activity, and (to my understanding) is determined entirely by assigning a separate LLM model the task of determining whether the user’s request was completed successfully or not. This is supplemented by user feedback in the form of thumbs up/down.
The problem I have with this is that we’re relying entirely on an LLM (specifically 4o-mini) to determine “successful” completion of a task. Here’s the output I received when feeding the classic “Strawberry has 2 Rs” AI mistake into the prompt the authors use:
{
“task_summary”: “The user asked the AI to count the number of ‘R’ letters in the word ‘Strawberry’.”,
“completed_explanation”: “The AI correctly identified that there are two R’s in the word ‘Strawberry’, fulfilling the user’s request.”,
“completed”: “complete”,
“speedup_50pct_explanation”: “The AI significantly reduced the time it would take to manually count the letters by instantly providing the correct answer.”,
“speedup_50pct”: true
}

Did it complete the task? I mean… technically, I guess. But we’re coming out of this with an indication that both the task was completed successfully and that AI handled it 50% faster than I could have, which is wrong on both counts.
I personally find it a stretch to use LLMs to gauge the success of LLMs when the question is “How good are LLMs at this?”.6 Couple that with the fact that the completion output is validated against user feedback data (thumbs up/down in Copilot) and the fact that this is a corpus of conversations that span both work and leisure contexts and you land in a place where “successful completion” loses most of its meaning. How am I going to know whether Copilot taught me French correctly?7 Might as well give it a thumbs up, seems good enough to me.
Scope
My best understanding of the interpretation for Scope is the proportion of user asks within IWAs of an occupation that AI can at least moderately assist with or provide, based on a six-point scale from none to complete. This is again classified using an LLM, but this one is validated by people who are not privy to the LLM outputs.
So a scope of 50% is saying half of all asks associated with IWAs of an occupation are kind of able to be performed by AI, but it’s also saying that half of all asks are less than kind of able to be performed. For reference, the highest scope I see in the scary list is 62% (Passenger Attendants), meaning that almost 40% of asks within that occupation are not meaningfully able to be assisted or performed by AI.
AI Applicability Score Interpretation
I want to reiterate, “applicability” does not mean “interchangeability”8, and that’s never implied by the authors. The AI Applicability Score, as it is defined in the paper, is simply a measure of impact AI might have on an occupation, via performance or assistance. My coffee mug impacts my crippling caffeine addiction, but it’s not replacing coffee. These components, and the final score, are averaged across both user goals and AI actions, so naturally knowledge work is going to show up most often in these lists because all these models do is gather and provide information to people. People know that’s what these models are good at, so it’s also going to be the largest share of what is asked for by users.
The 4 most frequently covered IWAs by AI actions are some variation of “provide information or general assistance”, and the 3 most frequently covered IWAs by user goals are some variation of “get information and respond to people”. The more of that you do in your job, the more likely you’re going to see your job pop up on one of these lists, that’s just how these work. That being said, the more of that you do in your job, the more likely it is that the accuracy of the work is important. Is that always the case? Of course not. But even in the cases where accuracy isn’t paramount, this report isn’t suggesting you are being replaced, it’s just saying “Hey, AI could probably help here.”
tl;dr
The Microsoft report isn’t saying your entire occupation is on the chopping block (or safe, for that matter). All it’s doing is listing jobs where people are already using AI for tasks related to the job and trying to quantify how often, how successfully, and how helpfully. These tasks are about as broad as you can get while still tying them to a subset of occupations, and naturally lean towards strengths of LLMs, namely gathering, summarize, and providing information.
- The high coverage numbers aren’t a reflection of how many people in the profession are using AI
- The completion numbers are, in my opinion, destined to be artificially high across the board
- The scope numbers still indicate that there’s a ways to go before AI is more than moderately helpful in most occupational tasks, much less replacing people doing these tasks.
At the end of the day, AI is not coming for your job9, and the most this report is trying to say is that AI might be helpful for some of your jobs, sometimes, maybe. Any other interpretation of this is clickbait, and folks, you’re not clickfish. Please stop falling for it.
Footnotes
Read “weeks old” at the time of writing.↩︎
arXiv.org “Working with AI: Measuring the Occupational Implications of Generative AI,” Page 32, Figure A5.↩︎
Have we reached semantic satiation yet?↩︎
arXiv.org “Working with AI: Measuring the Occupational Implications of Generative AI,” Page 4, Table 1.↩︎
If it did, I could use “applicable” and “interchangeable” applicably↩︎
I am! Watch out!↩︎